



ChatGPT is a conversational AI system built on large language models (LLMs). While it feels like a natural dialogue partner on the surface, its responses come from a complex technical pipeline running in the background.
To understand how ChatGPT works, it helps to break the system into several layers. At its core, ChatGPT is a Transformer-based model trained on vast amounts of text. On top of that foundation, additional training steps align it with human expectations. When you type a prompt, the model generates an answer one token at a time, guided by both statistical patterns in data and its reinforcement learning from human feedback.
But ChatGPT does more than just predict text. It includes built-in safeguards that block harmful or inappropriate outputs. It can augment its knowledge through retrieval, pulling in external documents or web content to provide timely and source-grounded information. When it surfaces sources, a ranking pipeline evaluates and reorders candidate documents, balancing freshness, relevance, and diversity before citations are attached to specific claims in the final answer.
This article takes a comprehensive look at how ChatGPT functions under the hood. We’ll explore:
- The training pipeline
- How responses are generated
- How safety layers work
- The retrieval process
- How ChatGPT's ranking algorithm determines which pages and passages make it into answers
Along the way, we’ll also look at personalization, knowledge cutoffs, and comparisons with search engines like Google. The goal is to give you a clear, detailed view of the mechanics, strengths, and limitations of ChatGPT’s backend.
ChatGPT combines three pillars:
- generation (LLM produces text),
- retrieval + ranking (external sources are gathered and ordered),
- safety + alignment (guardrails and human preferences shape the final output).
Core model and training
At the foundation of ChatGPT is the Transformer architecture, a deep learning design introduced in 2017 that has since become the standard for large language models. ChatGPT uses a decoder-only Transformer, which is optimized for generating text sequences. Its key innovation is the self-attention mechanism, which allows the model to weigh the importance of different words in a sequence relative to one another. Unlike older recurrent models that processed inputs step by step, Transformers handle sequences in parallel, making them far more efficient to train on large datasets.
Pretraining
During pretraining, the model is exposed to a vast corpus of publicly available text and licensed data. The objective is simple but powerful: predict the next token in a sequence given the previous ones. Repeated across billions of examples, the model learns statistical associations between words, phrases, and concepts. The outcome is a broad but unaligned capability to generate text that resembles human language.
Alignment through supervised fine-tuning and RLHF
Once pretraining is complete, the model undergoes additional fine-tuning to make it more useful and safe in a conversational context. This process has two main stages: supervised fine tuning (SFT) and reinforcement learning from human feedback (RLHF).
- Supervised fine-tuning (SFT): Human annotators provide example prompts and high quality answers. The model is then trained to reproduce these responses, aligning it more closely with the types of outputs users expect.
- Reward modeling: A reward model is trained by showing human evaluators multiple responses to the same prompt and asking them to rank which they prefer. Reinforcement optimization (PPO): Using reinforcement learning, the base model is fine tuned to maximize the reward model’s scores. This is often implemented with Proximal Policy Optimization (PPO), which stabilizes the training process.
Mini-reference: post-training steps
Important distinction
These alignment steps don’t add new factual knowledge. Instead, they reshape how the model presents information: how cautious or confident it sounds, how it balances creativity with accuracy, and how it responds to sensitive requests. ChatGPT’s factual knowledge is fixed at the point of training; alignment only governs its behavior on top of that base.
Inference and reasoning
Once training and fine-tuning are complete, ChatGPT can be deployed to generate answers in real time. This stage is called inference.
When a user submits a prompt, the model does not output an entire paragraph at once. Instead, it generates text one token at a time. A token may be a whole word, part of a word, or punctuation, depending on the language and context. Each new token is chosen based on the probability distribution calculated over the model’s vocabulary, conditioned on all the tokens generated so far. The process repeats until the model decides the sequence is complete.
Decoding strategies
To control text generation, different decoding strategies can be applied:
These strategies let the system balance coherence, creativity, and variability in its responses.
Reasoning ability
ChatGPT’s reasoning ability emerges from these probabilistic steps. The model does not “think” in the human sense, but training patterns can mimic logical chains. For example, when prompted to “think step by step,” the model expands its output into intermediate steps that resemble reasoning. This is known as chain-of-thought prompting.
However, this reasoning is approximate. Because the model lacks an internal fact-checking mechanism, it can produce confident but incorrect statements - often referred to as hallucinations. While retrieval-augmented generation reduces this risk by grounding answers in external sources, hallucinations remain an inherent limitation of predictive text models.
TL;DR
- Inference = token-by-token text generation.
- Decoding strategies shape style: greedy (safe, bland), sampling (creative, variable)
- “Reasoning” is simulated pattern expansion, not true logical thought.
- Hallucinations are an unavoidable limitation without external grounding.
If your content isn’t crawlable, structured, and trusted, reasoning models simply won’t find it. The future of visibility now depends on how well your website communicates meaning to both humans and machines.
Safety and moderation
Alongside its training and inference pipeline, ChatGPT includes multiple safety layers designed to reduce harmful or inappropriate outputs. These safeguards operate at different points in the system.
Model-level safeguards
At the model level, ChatGPT is trained to recognize and refuse requests that fall into restricted categories. This alignment is built into the fine-tuning process, where human feedback guides the model to avoid generating certain types of content, such as explicit instructions for illegal activity or highly toxic language.
These refusals are not hard-coded rules. Instead, they are learned behaviors, meaning the model develops a tendency to decline in specific situations.
External moderation system
Beyond model-level behavior, an external moderation system provides another layer of filtering. OpenAI’s Moderation API screens both user inputs and model outputs for categories such as:
- hate speech
- sexual content
- violence
- self-harm
Filtering can happen before the model generates a response, or after, to block unsafe completions.
It's important to note that the moderation system isn’t perfect, and can product:
- False positives: harmless queries may be blocked.
- False negatives: unsafe content may slip through.
By combining model-level refusals with external filters, ChatGPT minimizes the likelihood of harmful responses reaching users, but cannot eliminate the risk entirely.
Retrieval-augmented generation (RAG)
Although ChatGPT is trained on vast amounts of text, its knowledge is fixed at the time of training. To overcome this limitation, it uses retrieval-augmented generation (RAG) to access more recent or specialized information.
How RAG works
Instead of relying only on memorized training data, ChatGPT can pull in relevant documents at runtime and incorporate them into its response. This makes the system more flexible, current, and better grounded in verifiable sources.
The retrieval pipeline typically follows these steps:
- Chunking: External documents are broken into smaller passages (a few hundred words each).
- Embedding: Each chunk is converted into a numerical vector that captures its meaning.
- Similarity search: A user query is embedded and compared against the document vectors to find the closest matches.
- Candidate selection: The most relevant chunks are pulled into ChatGPT’s context window.
- Response generation: The model generates an answer that blends its trained knowledge with the retrieved material.
In some cases, ChatGPT extends beyond pre-collected documents by using partner search APIs. These APIs fetch relevant web pages, which are then processed through the same pipeline: chunked, embedded, and scored for relevance before being included.
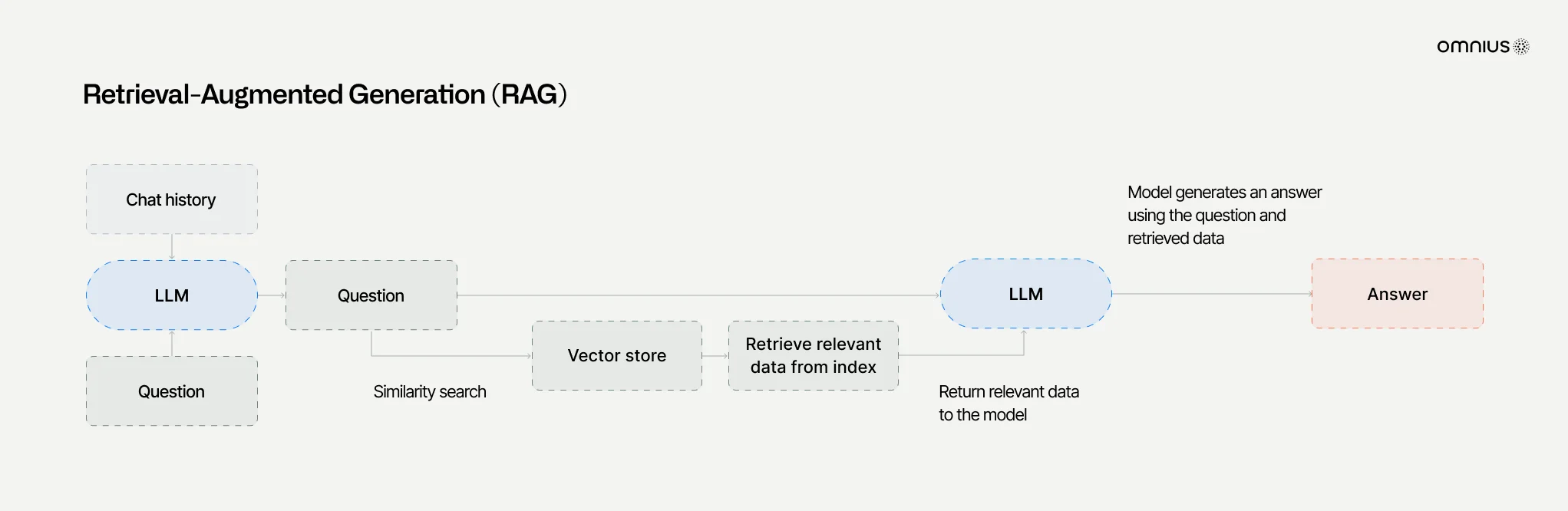
ChatGPT does not crawl the web directly; it depends on existing providers or structured data feeds.
This retrieval capability allows ChatGPT to:
- answer questions about recent events (beyond the training cutoff),
- access niche or specialized domains,
- reduce hallucinations by grounding responses in external sources.
Candidate gathering
When ChatGPT retrieves information from the web or connected sources, it does not rely on a single query. Instead, it uses a multi-step search pipeline designed to maximize both coverage and relevance.
The process begins with query rewriting. A user’s original prompt may be expanded into multiple reformulated queries, each emphasizing different aspects of the request. This “query-fan-out” approach helps capture results that may be phrased differently across the web.
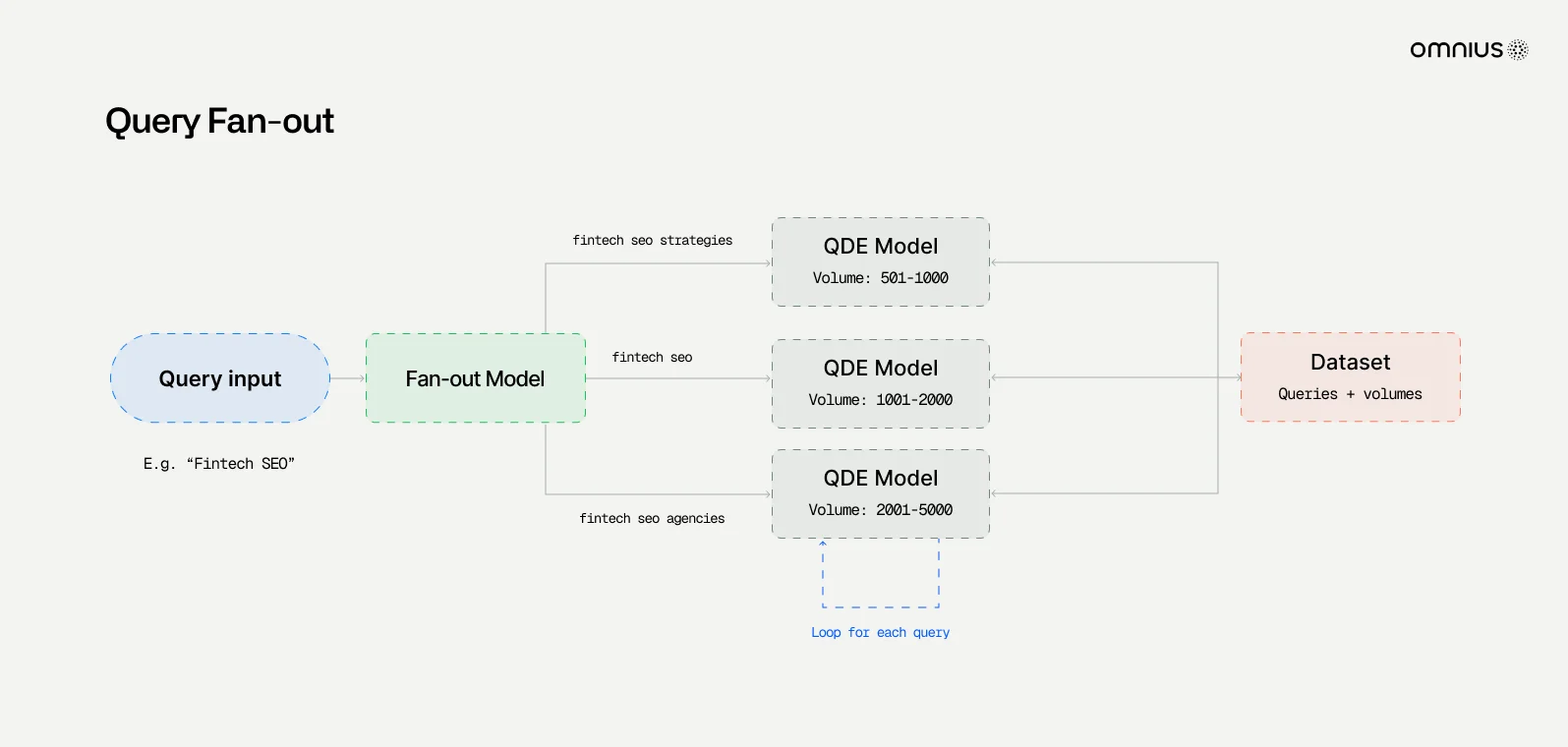
These reformulated queries are sent to partner search indexes. ChatGPT does not crawl the web independently; it relies on existing providers. The combined results form the initial candidate pool of documents.
In some cases, ChatGPT can use its own search bot for specific domains. For example, OAI SearchBot may fetch content directly from sites, respecting robots.txt rules and structured feeds. Metadata from sources like e-commerce product feeds can also improve relevance in shopping-related results.
Filtering and deduplication
Because multi-query expansion generates overlapping results, the candidate pool is often larger than necessary. To manage this:
- Deduplication: near-identical results are merged.
- Lightweight scoring: documents are quickly evaluated for clear relevance.
- Filtering: results that do not match the query intent are removed.
The result is a cleaner, more manageable set of candidates. These documents then move into the ranking pipeline, where more advanced scoring determines which passages are ultimately surfaced in ChatGPT’s final answer.
Ranking process
Once a set of candidate documents has been gathered, ChatGPT applies a multi-layered ranking pipeline to decide which sources should be surfaced in its final response. This stage is critical because it directly influences what information users see.
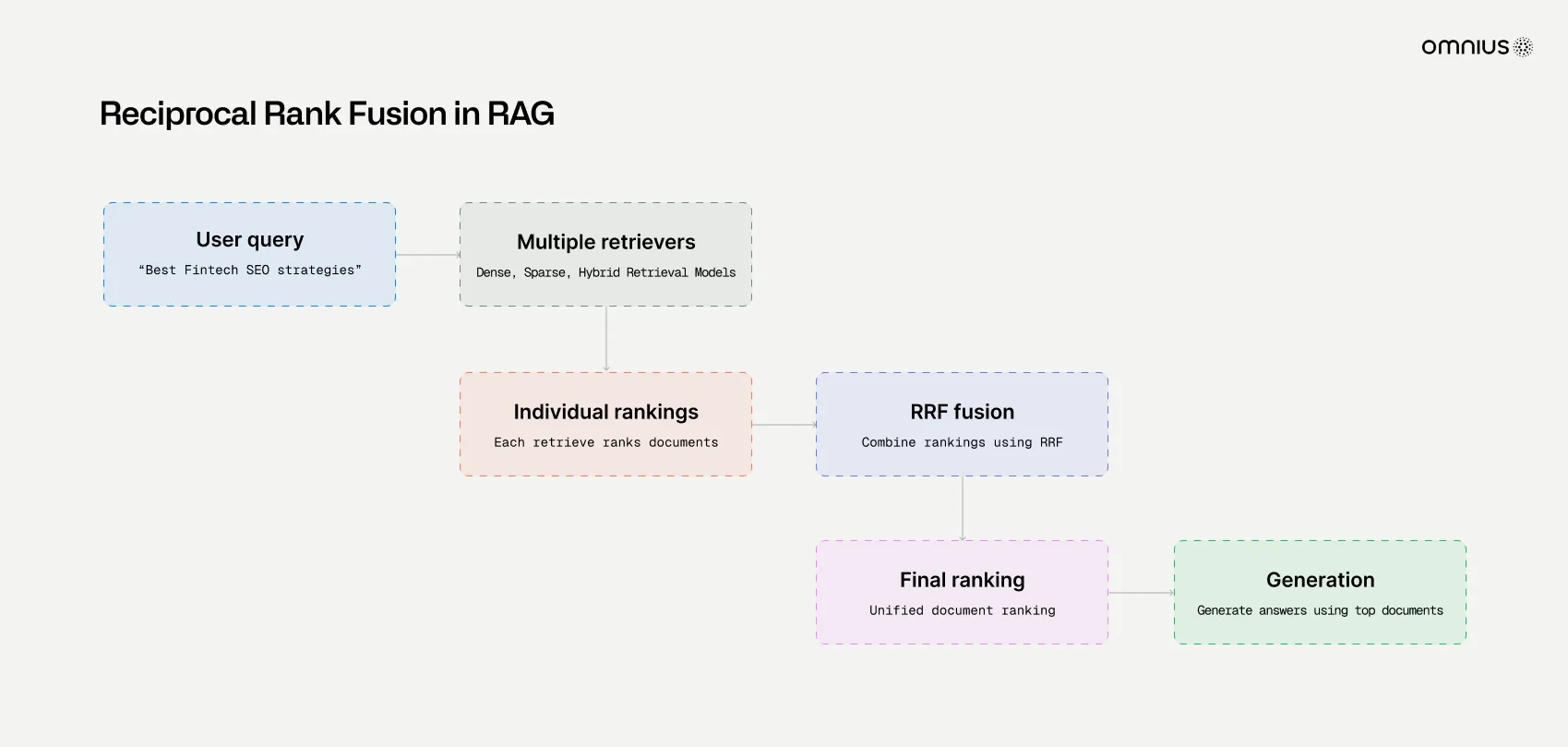
1. Reciprocal rank fusion (RRF)
The first stage often uses Reciprocal Rank Fusion (RRF). This method boosts documents that appear across several query rewrites. Even if a document is not the top match for a single query, repeated appearances signal broader relevance, helping to rank higher in ChatGPT.
RRF combines rankings from multiple query rewrites. If a page consistently shows up across different versions of the query, it gets pushed higher in the list - even if it wasn’t #1 in any single query.
Technically, RRF assigns scores using:
- RRF(d) = Σ (1 / (k + rank(d, q))) across all queries q
- where k is a constant (e.g., 60).
This simple but effective formula rewards consistency across queries rather than absolute position in any single list.
2. Neural reranking
After fusion, candidate documents go through neural reranking. Here, a more advanced model scores each passage’s semantic relevance to the user’s query.
Two main types of rerankers are used:
- Cross-encoders: compare query and passage jointly, yielding high accuracy but at higher computational cost.
- Bi-encoders: embed queries and passages separately, making them faster but less precise.
In practice, bi-encoders are often used for the initial cut, while cross-encoders handle the final reranking for precision.
3. Quality signals
Ranking also incorporates quality signals, which help refine results beyond semantic relevance:
- Freshness: favors recently updated content (e.g., news, financial filings, industry reports).
- Intent detection: ensures documents align with the user’s real goal
- Domain vocabulary: highlights authoritative use of technical or specialized terms.
- MIME/source filtering: emphasizes certain types of documents (articles, datasets, product listings).
- Source type biasing: trusted domains (e.g., government sites, enterprise docs) may receive higher weight.
These signals work together to surface documents that are not just topically related but also timely, trustworthy, and context-appropriate.
4. Diversity constraint and passage-level answerability
Instead of selecting only near-duplicate passages, ChatGPT's algorithm enforces a diversity constraint. This ensures that final answers are grounded in multiple perspectives rather than dominated by a single source.
At the same time, the ranking pipeline emphasizes passage-level answerability. Passages that directly address the user’s question are scored higher than those that are merely tangential. This improves the likelihood that the final answer is well-supported and precise.
5. Private & connected sources
When users connect personal or organizational accounts, lighter scoring is applied to those results. This ensures that private or enterprise data is smoothly integrated into the ranking without overwhelming broader search relevance. For example, a company wiki page might appear alongside authoritative public sources, but it will not dominate unless it is clearly the most relevant.
Synthesis and attribution
After the ranking process determines which documents are most relevant, ChatGPT moves into the synthesis stage. Here, the model combines the top-ranked sources with its own trained knowledge to generate a final response.
1. Claim planning
Instead of writing freely, the model is guided to identify key claims that need to be covered in the answer. This makes the output more structured and ensures that major parts of the user’s question are addressed.
2. Grounding
For each claim, the system checks whether there is supporting evidence in the retrieved documents. This is known as grounding - anchoring statements to external text passages rather than relying only on the model’s memory.
3. Conflict resolution
When multiple sources provide conflicting information, ChatGPT applies a conflict resolution step. It weighs credibility and consistency, often preferring fresher or more widely corroborated passages. While not perfect, this reduces the risk of presenting weak or contradictory evidence as fact.
4. Selective citation
Citations are attached at the end of this process. Instead of linking every document used, ChatGPT selects sources that directly support specific claims. These citations are tied to particular spans of text, allowing users to verify the information.
Personalization and memory
While ChatGPT is primarily designed as a general-purpose assistant, it does incorporate limited forms of personalization. These features influence query interpretation and response style, but they are not the kind of deep individual profiling used in some recommendation systems.
The most common personalization factor is general location. For instance, a query about “best payment processor” may be interpreted differently depending on the user’s region. This is a lightweight adjustment that helps answers stay contextually useful without building a detailed user profile.
Another layer comes from ChatGPT’s optional Memory feature. When enabled, Memory allows the system to retain certain information across conversations, such as a user’s name, preferences, or recurring topics of interest. This information can then guide query rewriting and response generation, making interactions feel more consistent and tailored over time.
It’s important to note that this personalization is limited in scope. ChatGPT does not rewrite its ranking system around individual users, nor does it maintain comprehensive behavioral profiles. Instead, these mechanisms offer modest improvements to relevance and continuity while keeping the model’s core functioning largely the same for all users.
Knowledge cutoff and timeliness
One of the most important constraints on ChatGPT is its knowledge cutoff. The model’s pre training only includes data available up to a specific point in time. Anything published or updated after that cutoff is not part of the model’s internal knowledge.
This limitation means ChatGPT cannot rely solely on memorized information to answer questions about recent events, evolving technologies, or ongoing developments. For example, if the cutoff is set to 2023, the model would not know about events in 2024 unless retrieval is enabled.
To address this gap, ChatGPT uses browsing and retrieval capabilities. By invoking web search, the system can access up-to-date documents through partner APIs. Retrieved content is then chunked, embedded, and ranked before being included in the model’s context window, allowing the assistant to generate answers grounded in current information.
This blend of static training data with dynamic retrieval creates a balance: the model provides stable, broad knowledge from its training, while browsing supplements it with fresher, situation specific details.
However, the browsing process depends on available sources and ranking algorithms, so timeliness is improved but not guaranteed to be comprehensive.
Comparison to Google Search
Although ChatGPT can retrieve using Google search and rank documents, its approach is fundamentally different from that of a traditional search engine like Google. Understanding these differences helps clarify why the two systems surface information in distinct ways.
Objective. Google’s primary goal is to return a ranked list of links that best match a user’s query. ChatGPT, on the other hand, aims to generate a synthesized answer directly in natural language. The difference in objective shapes every other part of the pipeline.
Unit of ranking. Google typically ranks entire web pages, with snippets extracted for context. ChatGPT focuses on passage-level ranking, identifying smaller sections of text that directly answer the question. This makes its results more focused but also more dependent on effective chunking and reranking.
Authority signals. Google’s ranking heavily weights authority signals like backlinks, domain reputation, and click-through rates. ChatGPT relies instead on semantic similarity, freshness, and intent detection. It does not apply traditional SEO-style authority metrics in the same way search engines do.
Freshness. Google continuously crawls and indexes the web to keep results up to date. ChatGPT uses retrieval through partner APIs, meaning it can provide fresh information but only when browsing is enabled and relevant sources are accessible. Without retrieval, ChatGPT is limited by its training cutoff.
User experience. Google presents a ranked list of documents, leaving it to the user to interpret and compare sources. ChatGPT produces a single synthesized response, citing specific passages where applicable. This reduces the need for manual searching but introduces risks if the synthesis process overlooks or misrepresents key details.
In short, Google functions as a comprehensive search engine, while ChatGPT operates as a conversational layer that blends generation with retrieval. Marketers adapting to this shift are increasingly using ChatGPT SEO prompts to test how their content performs in conversational queries, identify semantic gaps, and understand which formatting structures trigger citations in AI-generated responses. Each has advantages, Google provides breadth and transparency, while ChatGPT offers convenience and contextualized answers, but their underlying systems and ranking logic are not interchangeable.
Biases, limitations, and unknowns
Despite its sophistication, ChatGPT has important biases and limitations that shape its outputs. Understanding these helps set realistic expectations about what the system can and cannot do.
Alignment bias. Because reinforcement learning from human feedback (RLHF) trains the model to reflect human preferences, ChatGPT develops stylistic and cultural biases. It tends to respond in ways that reflect the values of its annotators and alignment process, which may emphasize caution, neutrality, or certain communication styles.
Political and cultural bias. Like any system trained on human-generated data, ChatGPT may reflect biases present in its training corpus. These can manifest in subtle ways, such as framing of political issues or representation of cultural perspectives. While alignment techniques aim to reduce harmful bias, complete neutrality is not possible.
Volatility of coverage. Retrieval introduces additional uncertainty. Depending on query rewrites, partner APIs, and ranking decisions, different sessions can yield different sources for the same question. This volatility means answers are not always consistent, even when the underlying facts are stable.
Opaque ranking weights. While we can describe the ranking layers, fusion, reranking, and quality signals, the exact weight assigned to each factor is not publicly disclosed. This opacity makes it difficult for outside observers to predict why one passage is chosen over another in a given case.
Reasoning limits. ChatGPT simulates reasoning through probabilistic text generation but does not truly reason in a human sense. It can produce logical-seeming explanations, but these remain vulnerable to errors and hallucinations.
Evolving capabilities. Features such as agentic browsing, which allow the model to interact more dynamically with external tools, continue to change the surface area of ChatGPT’s behavior. This makes the system more flexible but also more complex to understand and evaluate.
Taken together, these biases and limitations highlight that ChatGPT is not an infallible knowledge engine. It is a powerful tool for generating and synthesizing text, but its outputs should be considered alongside traditional search engines, direct sources, and critical human judgment.
Conclusion
Despite these strengths, ChatGPT comes with limitations. Its training and alignment introduce biases, retrieval can be inconsistent, and ranking decisions remain partly opaque. Reasoning is approximate, and the system’s capabilities continue to evolve with new features like agentic browsing.
For users, the key takeaway is that ChatGPT is a generative system augmented by retrieval and ranking, not a definitive knowledge base. It is most effective when seen as a powerful assistant for generating and grounding information, with its outputs evaluated critically and supplemented by direct source verification when accuracy matters.
Contact us and discover how AI-driven retrieval and ranking can transform your strategy.
Keep Learning
How to Rank on ChatGPT: 6 Tips to Boost AI Visibility
ChatGPT SEO Agency | Boost Your AI Search Visibility
The ChatGPT 52% Referral Crash: Why Betting on One Organic Channel Can Be a Risk
37 Best ChatGPT SEO Prompts to Use in 2026





.png)

.svg)








.svg)

















