



For the last two years, marketing and tech circles have proclaimed that “SEO is dead.”
In reality, SEO has never been more important. The reason: OpenAI’s GPT-5 and other large language models are shifting from memorization to reasoning over external knowledge sources, via browsing, tools, and retrieval.
In other words, AI search is no longer about packing encyclopedias into neural weights, it’s about retrieving, evaluating, and reasoning over information on demand.
This turns SEO from a nice-to-have into core marketing infrastructure.
Why GPT-5 isn't focused on memorization
Older language models gained power by ingesting ever more text. GPT-3.5 and GPT-4 were, in effect, massive neural encyclopedias. GPT-5 non-accidientialy breaks from that pattern.
OpenAI describes GPT-5 as a unified system: a fast model for most queries, a deeper reasoning model for harder problems, and a router that chooses which to use. The core is not bigger memory but smarter routing and deeper reasoning.
In June 2025, Altman reiterated his vision of a “very tiny model with superhuman reasoning,” emphasizing tools and context over storing facts inside weights.
The message from OpenAI is consistent: intelligence comes from reasoning plus retrieval, not memorization, and considering ChatGPT is leading the LLM race, this is the future of this whole industry.
Why is this happening?
This change wasn’t just philosophical, it comes with very practical reasons.
Training GPT-5 required enormous resources. Independent estimates suggest training GPT-5 likely costs hundreds of millions of dollars (often quoted as “>$500M”). Scaling further would have required tens of thousands of H100 GPUs running for months and consuming massive amounts of electricity.
Estimates for earlier models put GPT-3 around $4–5M and GPT-4 near $100M, showing how sharply costs have risen. GPT-5 is believed to be several times more expensive again.
This is not an isolated case. A 2024 Epoch AI/Stanford study found that the cost of training frontier AI models has been rising at about 2.4× per year since 2016, with the most compute-intensive runs projected to exceed $1 billion by 2027.
Additionally, OpenAI has encountered the “data wall” - a shortage of high-quality training data. Synthetic data generation couldn’t keep pace, even with significant human oversight.
In response, the company focused not on building a larger model, but on making reasoning more efficient.
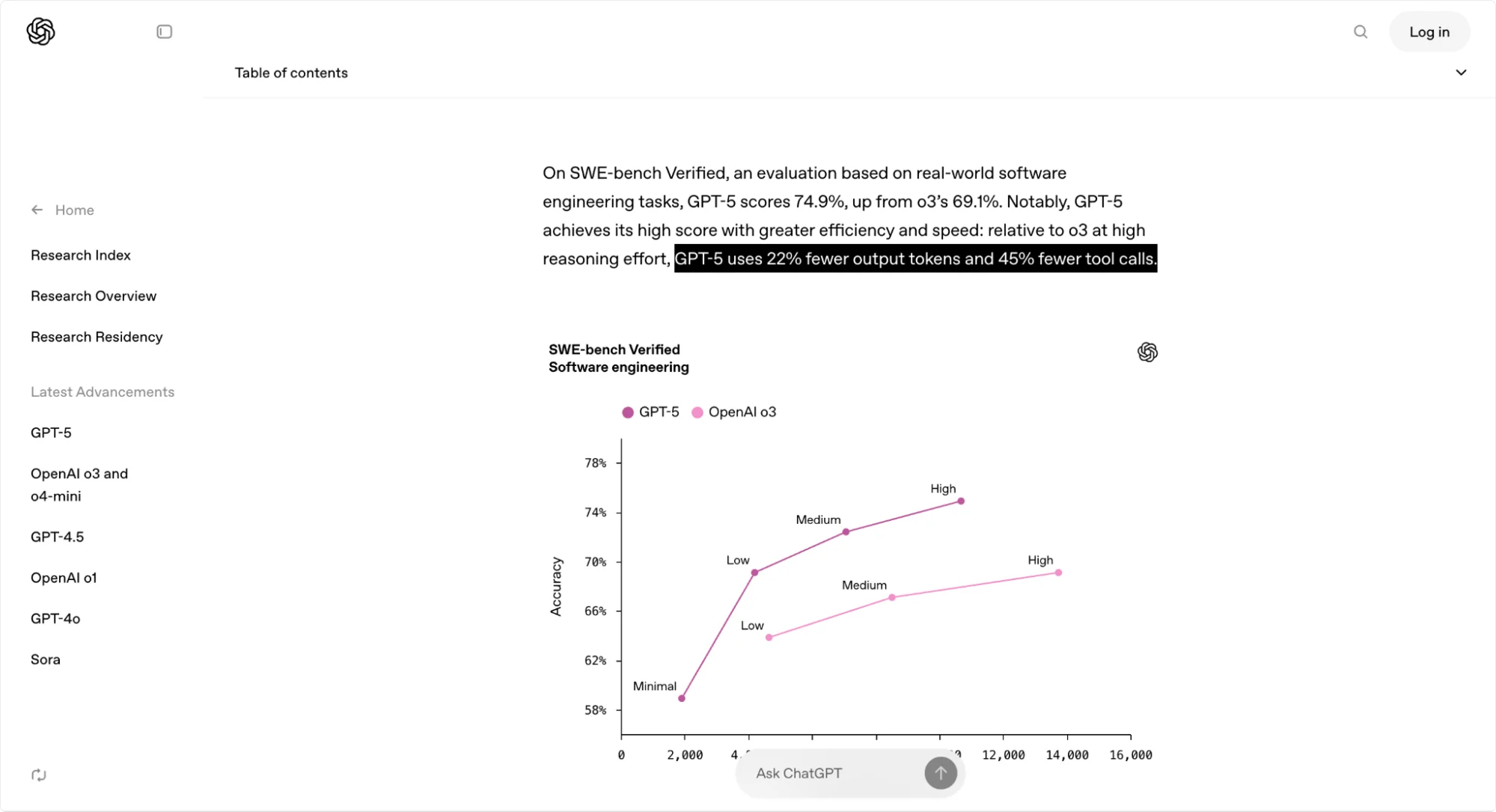
OpenAI’s documentation explains this choice: at high reasoning settings, GPT-5 uses 22% fewer output tokens and 45% fewer tool calls than o3, while still delivering better results.
The Pro variant is designed to further improve real-world accuracy and reduce hallucinations compared to earlier models, using dynamic routing to allocate compute where needed.
Why prioritizing reasoning over knowledge storage makes sense?
Benchmark data shows why reasoning has become more important than raw memorization.
On coding tasks, GPT-5 reaches 74.9% on SWE-bench Verified (OpenAI). External trackers report around 94% on the AIME 2025 math benchmark, depending on setup and tool use.
GPT-5 Pro is reported to further reduce hallucination rates. OpenAI’s system card confirms that reasoning mode reduces hallucinations, deception, and sycophancy compared to earlier models.
Grounded models need external knowledge
Researchers and OpenAI’s own evaluations show that GPT-5 performs significantly better when web search is enabled. Without external grounding, it can miss even straightforward technical details; with retrieval, it not only answers correctly but also provides richer context.
This reflects GPT-5’s deliberate design tradeoff: the model relies less on memorized facts in its weights and instead focuses on reasoning over retrieved information.
Connecting to ground truth
Nick Turley, head of ChatGPT at OpenAI, explained the reasoning behind adding search directly to ChatGPT. In an August 2025 Verge interview, he said the right product is “LLMs connected to ground truth,” noting that grounding significantly reduces hallucinations.
This approach allows reasoning models to verify their answers against reliable sources. Without external data, the model has to guess. With retrieval, it can cite authoritative information and deliver more trustworthy results.

Efficiency gains
Interestingly, retrieval doesn’t slow GPT-5 down, but makes it more efficient.
According to OpenAI’s system card, GPT-5 Thinking uses 50–80% fewer output tokens than o3 while delivering stronger results across visual reasoning, coding, and graduate-level scientific problem solving.
The Pro variant achieves superb accuracy in math, coding, multimodal understanding, and health. It also reduces hallucinations on factual benchmarks compared to o3.
These gains come from improved reasoning algorithms, smarter routing, and dynamic tool calls rather than simply increasing parameter counts.
Understanding agentic and interpretative layers
AI search models use multiple subsystems to deliver answers, notably two distinct layers that build on traditional retrieval:
Agentic layer – the strategic layer. It decides how to fulfill a query, reformulates questions if needed, and chooses which results to pull. Over time, platforms like the OpenAI Agent are expected to evolve this layer into a true personal assistant capable of handling tasks such as booking appointments, sending emails, and conducting independent research.
Interpretative layer – the presentation layer. It combines retrieved results, the user’s query, and metadata into a coherent answer. This is what produces the final narrative or conversational response.
At their core, they remain retrieval engines that pull information from already existing sources, that are additionally layered and/or filtered by AI.
Agentic retrieval and metadata extraction
We can go deeper into the analysis of how GPT-5 handles retrieval. This, above called the Agentic layer, process happens in two steps:
- The search action returns snippets rich in metadata – authors, dates, versions, ratings.
- The agent may use this metadata to decide which URLs to open for deeper reading.
Instead of prompting with raw data, the model works with references tied to structured metadata, consistent with how retrieval-augmented generation systems are designed.
GPT-5 and similar models can parse machine-readable details such as authors, publication dates, release versions, and even structured lists across different content types when this metadata is available.
This highlights why structured data (JSON-LD, microdata, schema markup) is critical. The retrieval layer favors sanitized, machine-readable snippets, and when a page is opened, the agent often processes a normalized representation rather than raw HTML.
Search vs. direct page access
There is also an important difference between search-mediated access and direct page access.
When an AI agent uses a search tool, the search engine pre-indexes JSON-LD, microdata, and RDFa markup, making structured data fully visible.
If the agent accesses a page directly (without search), server-rendered JSON-LD is still visible in the raw HTML, but many AI crawlers do not execute JavaScript. This means that JSON-LD injected client-side via JavaScript may be missed, leaving only structured data embedded directly in the HTML (such as microdata or RDFa) reliably accessible.
What should we do about this?
As LLM engines evolve toward direct API interactions, content creators should continue using JSON-LD as the primary structured data format and ensure it is server-rendered. Adding microdata or RDFa can serve as a fallback for agents that cannot process JavaScript-based markup.
Real-time retrieval and query “fan-out”
GPT-5 resets content retrieval through live retrieval across multiple modalities. The model dynamically decides between using its internal knowledge and pulling fresh web sources for each query.
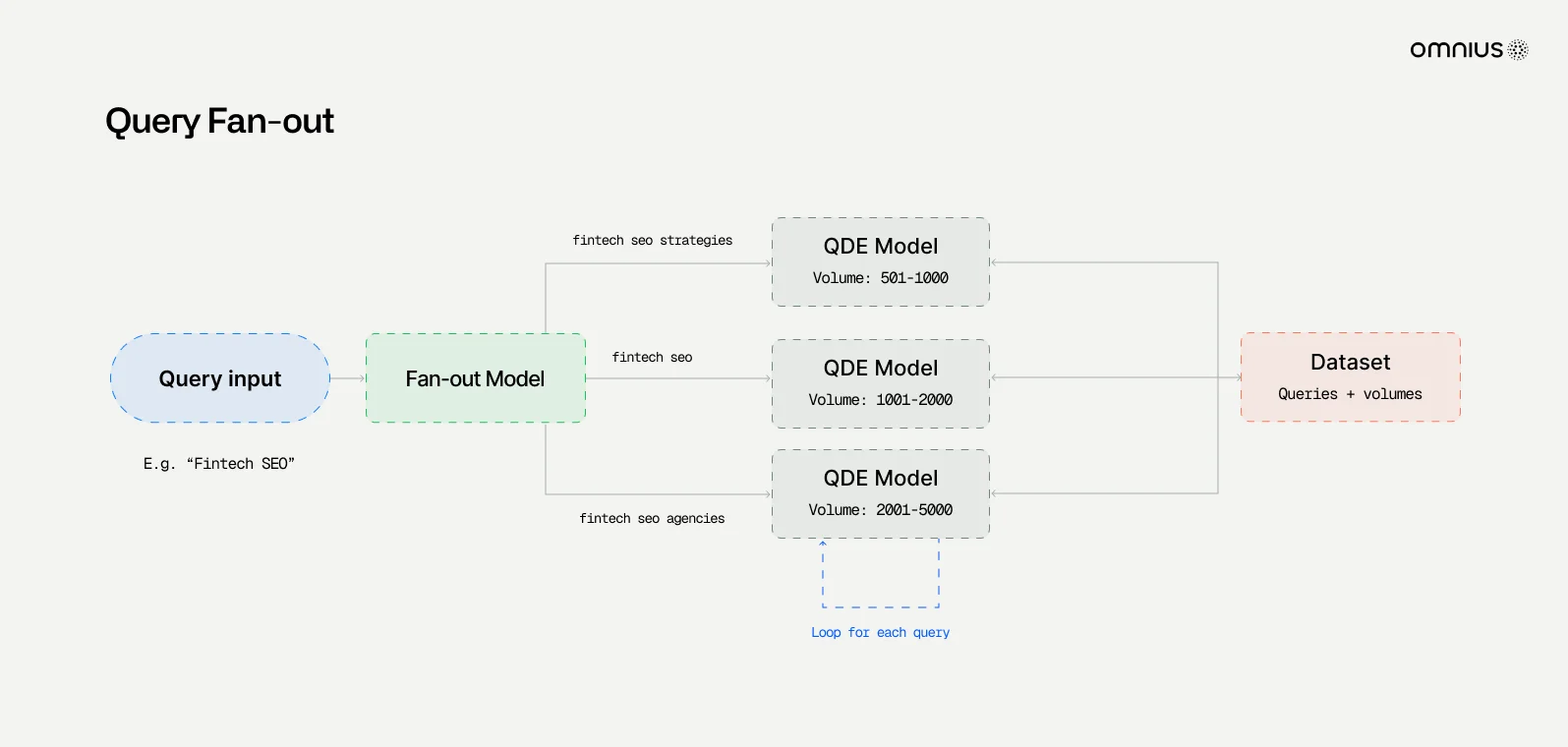
A key feature worth remembering here is a "query-fan-out.”
GPT-5 can break a question into multiple sub-questions, retrieving relevant pieces of information from across the web before synthesizing an answer.
This architecture has greatly reduced the lag between publishing content and being referenced in AI answers. What used to take weeks or months can now, in many cases, happen within hours.
Sites with clean internal linking, updated sitemaps, and fast rendering benefit most, as this approach puts new demands on content. Pages need to be machine-ready with clear headings and FAQs. Topical hubs and interlinking help AI agents retrieve multiple intents from a single structure. Models also favor structured formats like tables and lists, and are more likely to cite content that combines depth with precise claims.
What reasoning-first LLMs mean for SEO?
Simply, reasoning needs retrieval in order to work. When models offload knowledge storage to external sources, content discoverability becomes the gating factor.
Reasoning systems can only deliver strong answers if they can find and trust content. If website pages aren’t crawlable, indexable, semantically clear, and authoritative, they won’t be selected or cited by AI.
Brand mentions and authority signals
Reasoning models don’t just rely on links, but also learn from brand associations.
GPT-5 and similar systems are trained on large datasets where brands appear repeatedly alongside certain topics. Over time, this builds entity associations that influence which sources are retrieved and cited.
Brand mentions are becoming nearly as influential as backlinks. Even without a direct link, repeated mentions across high-quality publications and forums can help AI models recognize your authority.
Other authority signals matter as well. Expert bylines, clear authorship, and external validation increase the likelihood that AI agents will select and cite your content.
Real-time “fan-out” changes the competition landscape
In the GPT-5 era, ranking for a single keyword matters less than being cited across many related sub-queries. As explained earlier, AI models decompose queries into dozens of related intents - a process they call the “fan-out effect”.
Pages that provide comprehensive answers, link to subtopics, and offer structured summaries are more likely to be cited across this wider query set. Publishing speed is also increasing in its importance as AI models can now explore new content within minutes, rather than months.
Opportunities and risks for SaaS and fintech companies
For SaaS and fintech companies, this AI search pyramid creates both opportunity and risk.
The opportunity lies in publishing comprehensive, structured content, such as white papers, product documentation, guides, and knowledge bases that AI agents can cite.
Companies that invest in machine-readable, authoritative resources today are more likely to be trusted sources for GPT-5 and its competitors tomorrow.
The risk is invisibility.
Firms that treat content as secondary may find themselves absent from AI-driven retrieval. Although the traffic coming from AI search is still relatively small, about 1–2% of all web search referrals as of mid-2025, it is growing very fast, and reportedly bringing higher quality traffic compared to traditional search engines.
Companies that fail to adapt risk missing a channel that will expand significantly over the next five to ten years.
Practical implementation
Traditional SEO followed a pipeline of:
Crawlability - indexability - rankability.
In the new iteration of search market, the pipeline now consists from:
Crawlability - indexability - semantic clarity - retrievability - citation worthiness.
Models like GPT-5 break queries into sub-questions and extract chunks of text for synthesis. To be included, your content must:
- Be citation-ready: Provide clear claims, data points, dates, and sources so AI can extract and cite them.
- Use structured markup: Employ JSON-LD and microdata to make metadata machine readable.
- Organize content semantically: Use headings and FAQs so each section can stand alone.
- Build topical hubs and internal links: Link related pages to help models retrieve multiple intents.
- Focus on topical authority: Develop depth in your subject area so AI agents trust and cite your site.
- Focus on the freshness of data: Update content regularly so retrieval layers surface the most recent information
Conclusion
GPT-5 is showing a critical change in the LLM industry, pointing out that the future of AI isn’t about models that memorize everything, but about models that can find, evaluate, and reason over the best available information.
Sam Altman’s statement about “a very tiny model with superhuman reasoning" and Nick Turley’s “LLMs connected to ground truth” explain this point pretty well.
OpenAI’s own system card and benchmarks confirm the trend. GPT-5’s efficiency gains, reasoning performance, and reduced hallucinations come from retrieval and dynamic tool use - not from raw memorization.
Therefore, contrary to the sensationalistic “SEO is dead” claims, SEO has become irreplaceable. Paradoxically, because AI models are now focusing on retrieval and reasoning, they depend more than ever on high-quality, structured information to source and signals to evaluate.
Start future-proofing your SEO today with Omnius & turn your content into an AI-ready resource that gets discovered, cited, and trusted.





.png)

.svg)








.svg)


























