



Claude SEO is the practice of structuring content, technical infrastructure, and brand signals so that Claude AI cites your company in its responses.
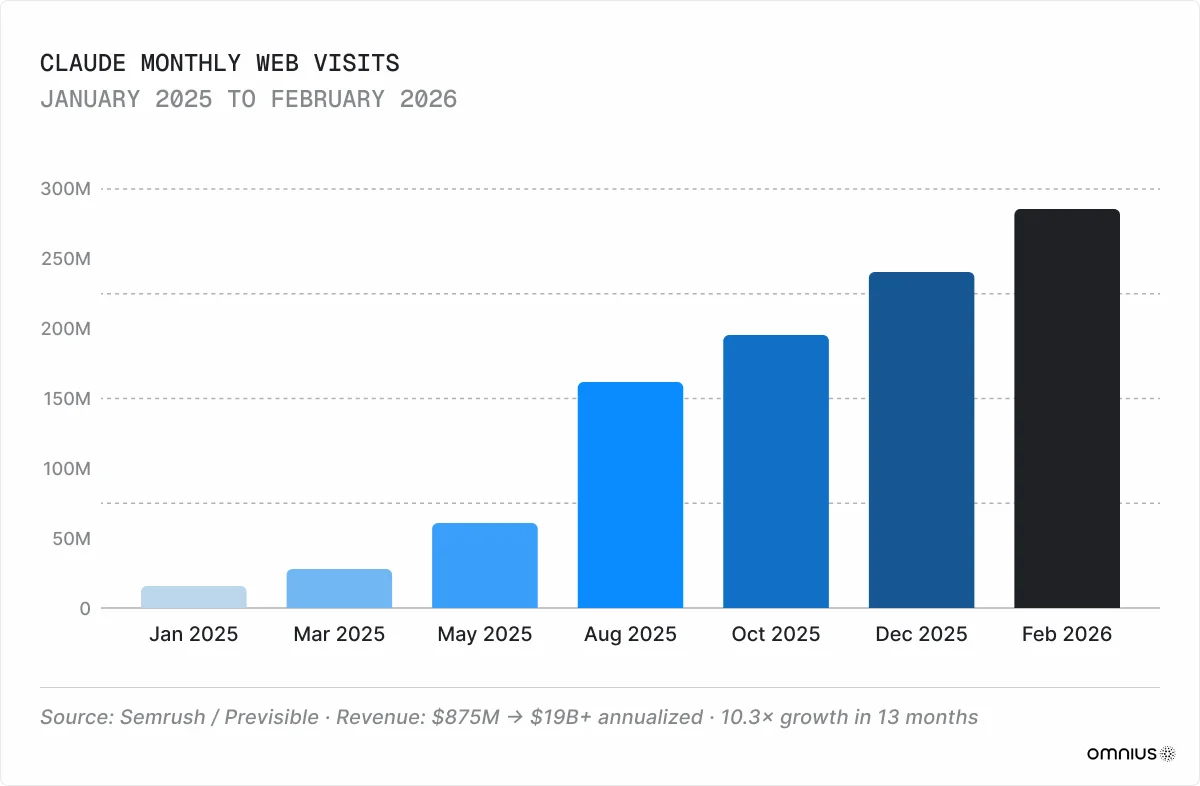
Claude has grown from 16 million monthly visits in January 2025 to 287 million by February 2026, Semrush reports. A year ago, it was primarily a productivity tool for writing and coding, but this has changed. According to our dataset of 11,000+ domains - mostly AI, SaaS, and Fintech websites - Claude is now the second-largest AI traffic source for B2B companies:
- It captures over 21% of AI-referred sessions.
- Its QoQ growth exceeds 76.2%.
- It has the highest engagement of all LLMs, with an average session of 3:27.
- Its user base skews heavily toward enterprise buyers, engineers, and technical decision-makers rather than casual browsers.
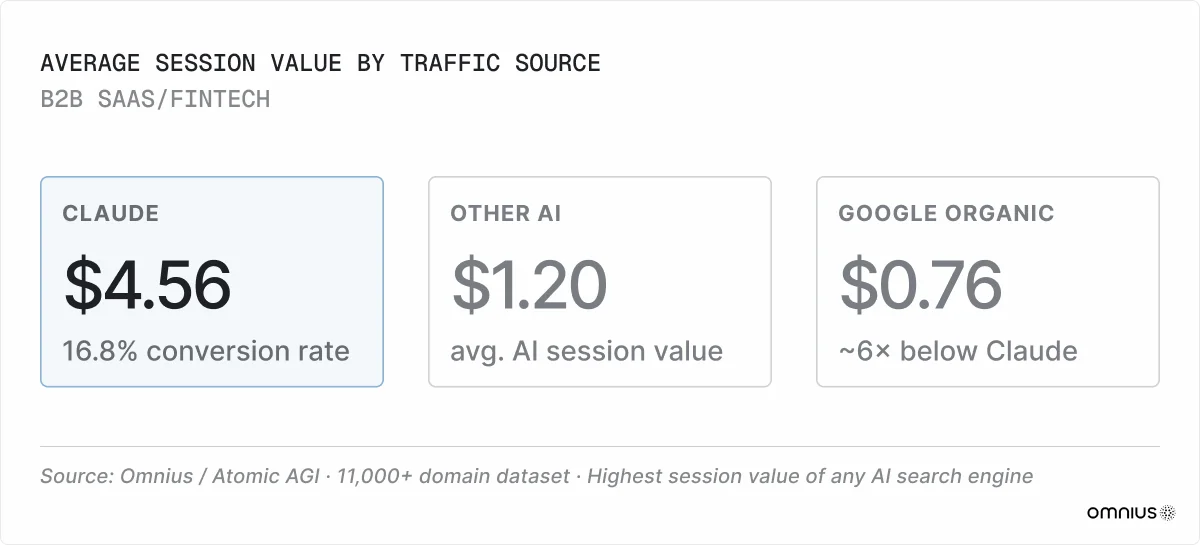
These patterns produce a 16.8% conversion rate and $4.56 average session value, the highest of any AI search engine and roughly 6× above Google organic.
73% of B2B buyers use AI in purchase research (Averi, 2026), and your ICPs are likely using Claude when deciding between you and your competitor. In this guide, we’ll use our research data to illustrate how Claude works and how you can end up in its citations.
Key Takeaways
- Claude distributes visibility differently from every other AI engine. It spreads citations across mid-market domains. Our model comparison data shows gaps exceeding 40 percentage points on the same domain.
- Claude’s retrieval system is complex and rigorous. It sources from Brave Search instead of Google, scores content through a dual semantic and keyword layer, and filters results through Constitutional AI, which penalizes promotional tone.
- Being cited on Claude requires four layers. Fix crawler access and Brave indexing first. Restructure content into self-contained passages, implement schema markup with named authors, and build third-party corroboration across independent sources.
- Measure visibility to understand your position and optimize accordingly. Track crawler access, citation flow rate, prompt coverage, share of voice, and citation sentiment.
Claude Distributes Visibility Differently From Other LLMs
We’ve found that Claude and other engines, such as ChatGPT, Gemini, and Perplexity, approach visibility in distinct ways across every segment in our dataset:
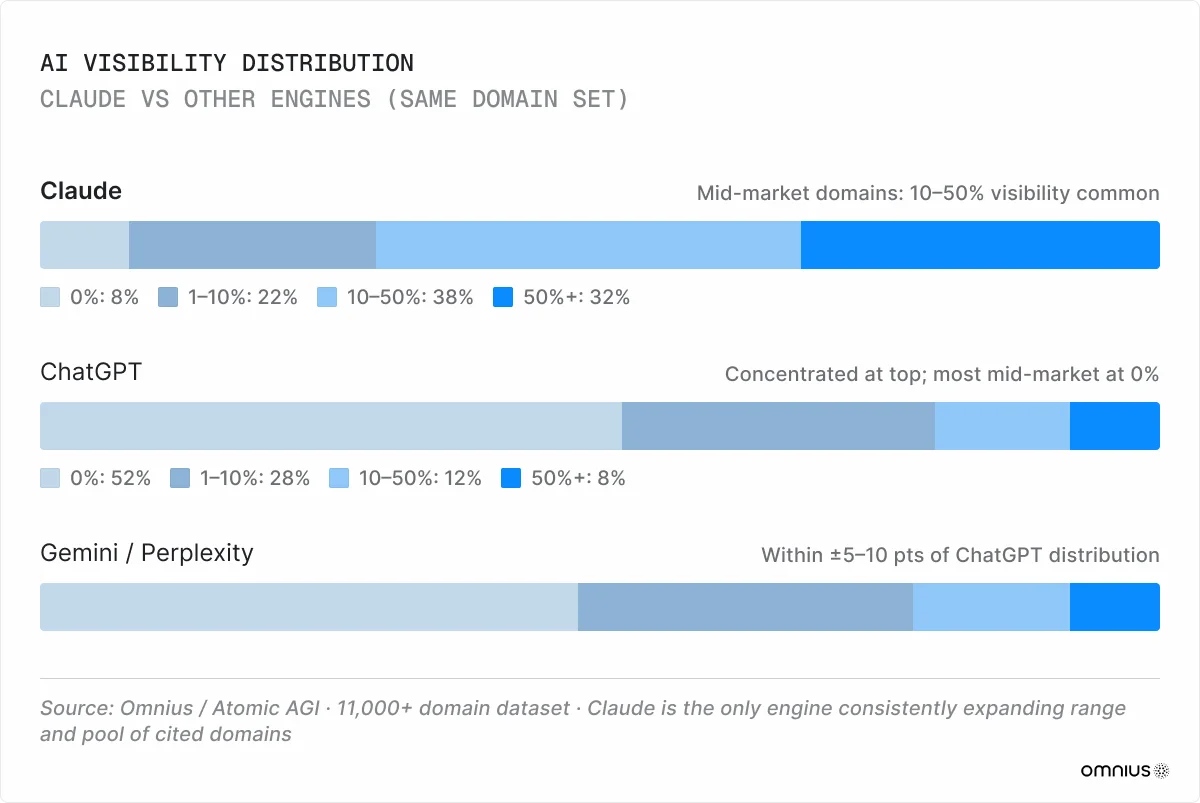
ChatGPT and other models concentrate visibility among a few high-authority domains, while Claude distributes exposure across mid-market domains. The two pools rarely overlap. A domain can receive a 5–10% visibility score with Claude while scoring zero with another model. Our AtomicAGI data spanning 11,000+ domains shows gaps between Claude and ChatGPT on the same domain that often exceed 40%.
The structural reason is the retrieval stack. Unlike most models, Claude uses Brave Search, which operates independently of Google and Bing. Brave has its own crawler and index, and doesn’t carry two decades of authority bias toward the same dominant publishers. Additionally, Anthropic’s Constitutional AI training rewards factual density over domain scale.
The result is a retrieval system that surfaces mid-market domains with genuine topical authority. A 500-page SaaS documentation site with structured, sourced content can outperform a Fortune 500 publisher running surface-level coverage of the same topic.
B2B companies that can't compete with enterprise domains on Google aren't locked out on Claude. Here, visibility is determined by content quality instead of budget or domain age. That makes Claude a genuine opportunity for mid-market brands willing to invest in structured, evidence-backed content.
Why Most Pages Are Invisible To Claude
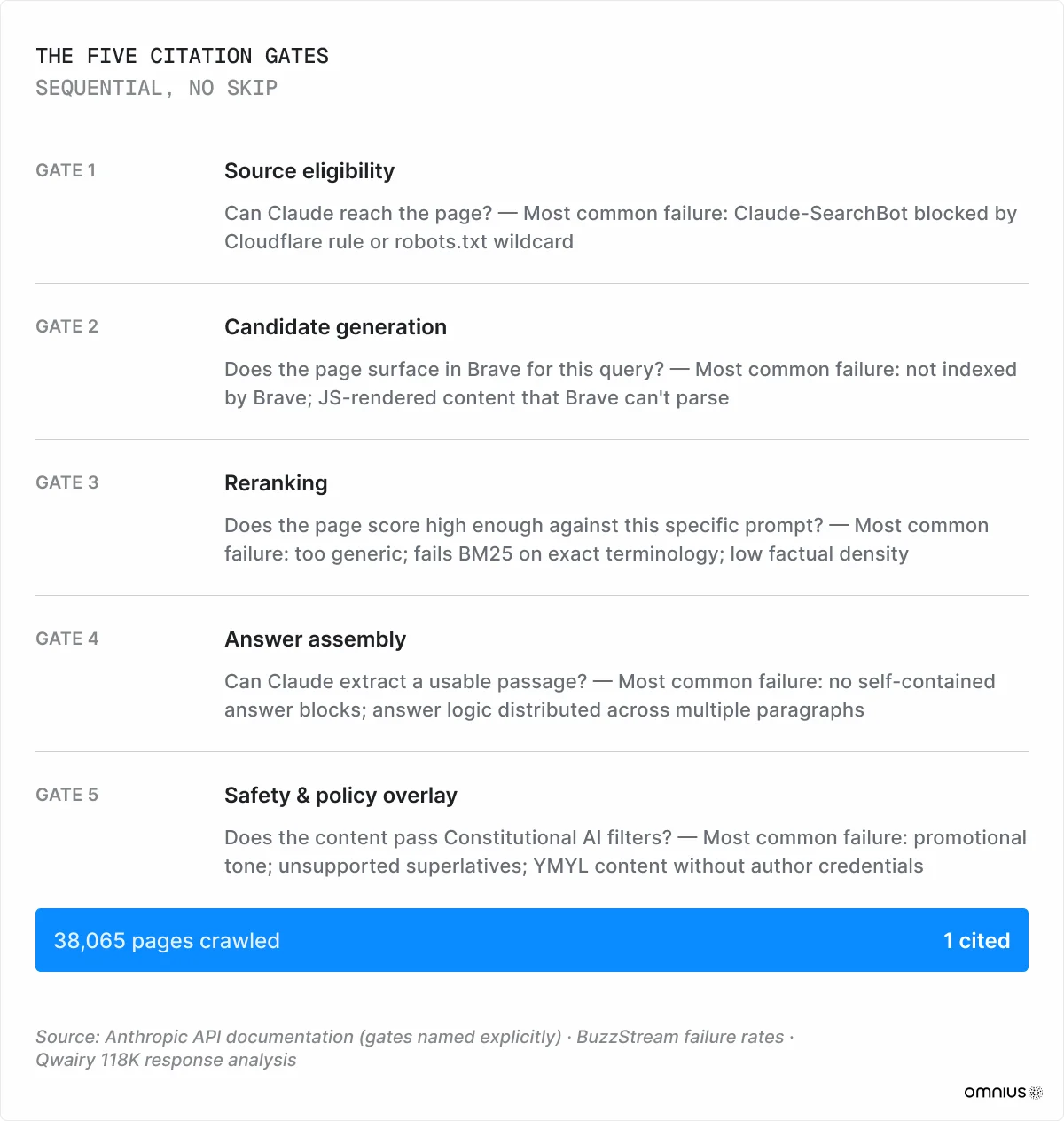
Qwairy’s 2026 AI citation analysis shows that Claude processes around 38,065 pages for every one it cites, and averages 5.67 citations per response. The vast majority of crawled content produces zero citation events, regardless of Google ranking, domain age, or content length.
The phrase "ranking on Claude" is misleading. There’s no global position, no page 1, no slot to hold. The question Claude asks is not "where does this page rank?" but "does this passage win the reranker for this exact prompt against better-sourced alternatives?" The answer changes with every query. The only durable advantage is content that reliably wins that selection.
Every page that enters Claude's pipeline must clear five sequential gates. Failure at any gate produces zero citations.
How Claude’s Retrieval System Works
Every query triggers a fresh retrieval event, and whether your content appears in the answer depends on clearing a specific pipeline, in order, every time. That pipeline starts with a search index most brands aren't optimizing for.
1. Retrieval
While most models use Google and Bing, Claude sources information from Brave Search. Profound's 2025 citation overlap study supports this claim: Claude's cited results align with Brave's top organic results at 86.7% (p < 0.0001).
At the same time, the source overlap between Claude and ChatGPT, which uses Bing, is only 20%. They are retrieving from different versions of the web. A page ranking #1 on Google can be completely invisible to Claude if Brave hasn't indexed it.

Three Crawlers
Anthropic operates three distinct bots: ClaudeBot, Claude-SearchBot, and Claude-User.
Blocking any one of these produces a different downstream failure. The biggest issue is blocking Claude-SearchBot, as it removes a brand from live retrieval entirely.
2. Scoring
When Claude retrieves content for a live query, it runs two searches in parallel. Semantic vector search matches conceptually, favoring topically rich, structured content. BM25 keyword search matches exact terms, favoring precise terminology and named entities. Both layers need to be satisfied. Content that writes around a topic without naming it directly fails BM25 regardless of how conceptually rich it is.
Anthropic's published implementation weights semantic and BM25 retrieval 80/20, combines them via Reciprocal Rank Fusion, then passes the candidate pool through a reranker.
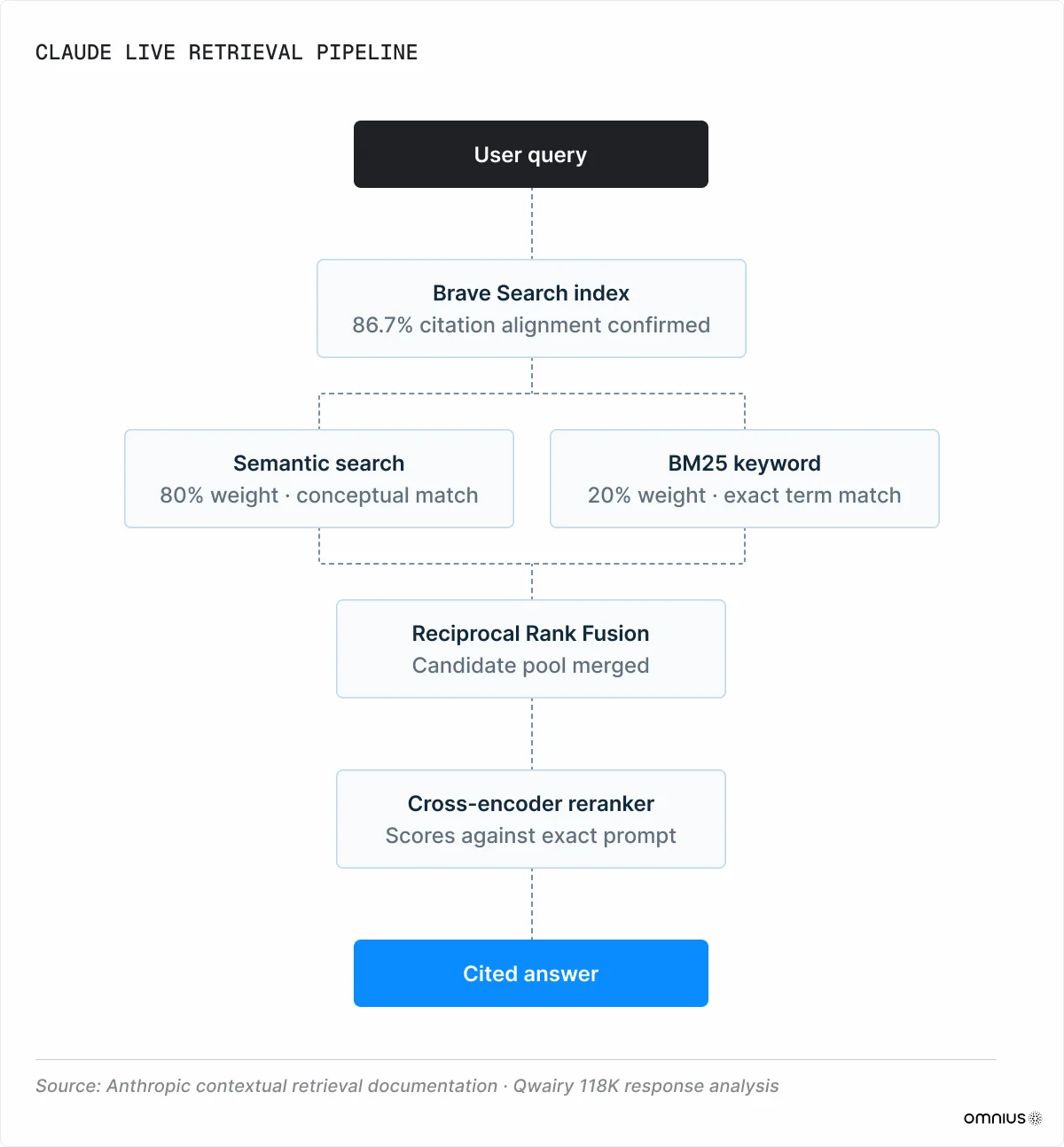
3. Reranking
The reranking stage is architecturally distinct from first-pass retrieval:
- First-pass embeds the query and each document separately, then compares them by vector similarity. This is fast enough to scan thousands of candidates, but it only captures general topical relevance.
- Reranking processes the query and document together, which allows it to evaluate how well a specific passage answers the specific question. This process is more accurate, but too expensive to run at scale, so it scores only the shortlisted candidates against the specific prompt, not a general topic representation. This is why two pages on the same subject can produce opposite outcomes on the same query.
Note: Anthropic confirms this retrieve-then-rerank pattern but has not disclosed the architecture of the reranker.
Passage Design Matters
Claude retrieves passages, not pages. Every section of a page competes independently for citation. A passage that depends on surrounding paragraphs for meaning loses that competition by default.
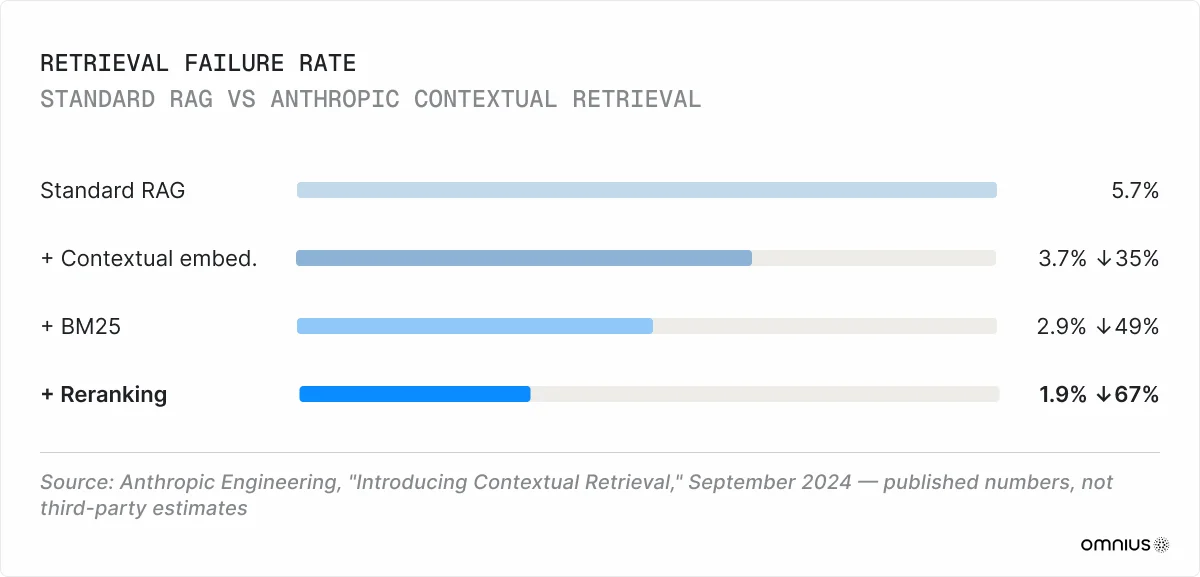
Standard retrieval-augmented generation (RAG) has a documented failure mode that exacerbates the issue: chunks extracted from documents lose their surrounding context entirely. Anthropic's Contextual Retrieval approach addresses this by prepending a short contextual summary to each chunk before embedding.
Contextual embeddings alone reduce retrieval failures by 35%. Add BM25, 49%. Add reranking, and retrieval failure drops by 67% compared to standard RAG. These are Anthropic's own published numbers.
Position within the page matters too. Growth Memo's 2026 analysis found 44.2% of all LLM citations are drawn from the first 30% of an article. If you use the top of a section or article for setup, transitions, or filler content, you’re wasting valuable real estate.

4. Answering
Claude's training methodology, called Constitutional AI, produces a unique citation bias. It shapes Claude’s behavior around a fixed priority stack: safety first, then ethical behavior, Anthropic's guidelines, and genuine helpfulness.
Content written in a marketing voice - leading with benefits, using superlatives without evidence, and framing a product favorably without qualification - scores lower at the final citation stage, even when it’s factually accurate. Constitutional AI favors content written in a neutral, analytical register.
This is a structural bias baked into model weights through training. The tone penalty on Claude is higher than on any other major AI engine.
Claude Research: A Higher Bar
Anthropic's premium Research feature uses an orchestrator-worker architecture. A LeadResearcher agent plans a strategy, spawns parallel subagents, and iteratively refines searches based on what each returns. This is not static single-shot retrieval. Research dynamically adapts to new findings across the full query cycle.
Citations in Research mode work differently. A distinct CitationAgent runs after the LeadResearcher synthesizes findings, auditing the completed report and mapping specific claims back to source locations. Citations are a post-synthesis verification pass. Content that survives the full pipeline has cleared a meaningfully higher bar than content that wins a single nearest-neighbor lookup in standard RAG.
Research uses approximately 15× more tokens than standard chat. Simple fact-finding runs one agent with 3–10 tool calls, while complex research deploys 10+ subagents. Research mode is usually triggered by high-intent queries that inform high-level purchasing decisions. Brands appearing in Research answers can reach the most commercially valuable user base.
7 Factors That Determine Claude Visibility
Seven properties determine whether a passage survives all five Claude citation gates consistently:
- Factual density
- Author credibility
- Primary source attribution
- Content freshness
- Corroborating source density
- Technical parseability
- Domain authority
1. Factual Density
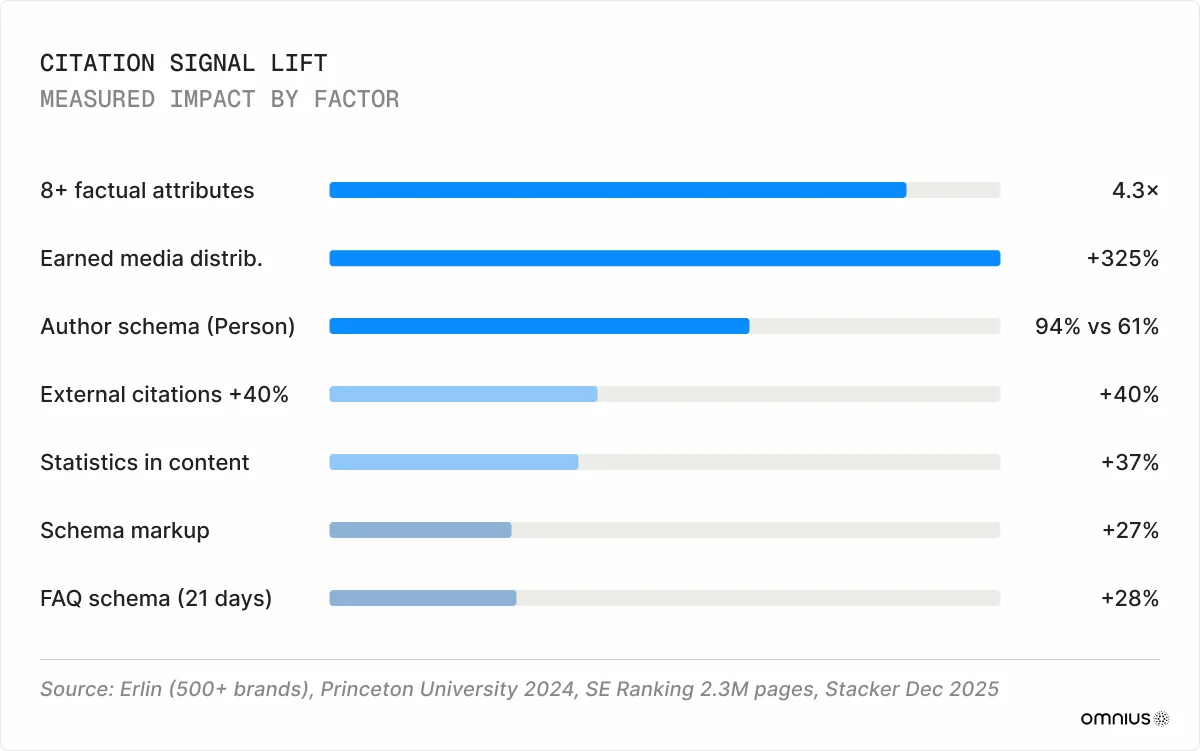
Content with 8 or more structured, verifiable attributes is cited 4.3× more often than content with fewer than 3 (Erlin, 500+ brand dataset). Each additional structured fact adds approximately 8.3% median AI coverage. Adding statistics increases citation frequency by 37%; adding attributable external citations increases it by 40% (Princeton University, 2024).
What you should do: Make sure every substantive claim in a passage can be verified by a third party without reading the surrounding context. Replace subjective benefit statements with specific, verifiable claims.
2. Author Credibility
When the Article schema explicitly declares a Person author entity, Claude cites content with 94% confidence, compared with 61% for plain text with no author markup (Erlin, 2026). Pages with visible author credentials have a 41% higher citation likelihood than uncredited content. An anonymous byline is a structural disadvantage, particularly for YMYL content, where Claude applies additional Gate 5 scrutiny.
What you should do: Attribute every piece of content to an individual with relevant expertise. Create a dedicated author bio page for each contributor, listing their role and credentials. Include institutional affiliation, such as company name, title, and relevant certifications. Link to the bio from every article they write using Article + Person schema.
3. Primary Source Attribution
Claude traces claims to their origin. Vague attribution earns less citation weight than concrete source names. It reduces passage-level citation confidence because Claude cannot verify the claim chain.
What you should do: Provide a named source, a date, and, where possible, a direct link to the primary document for every data point.
4. Content Freshness
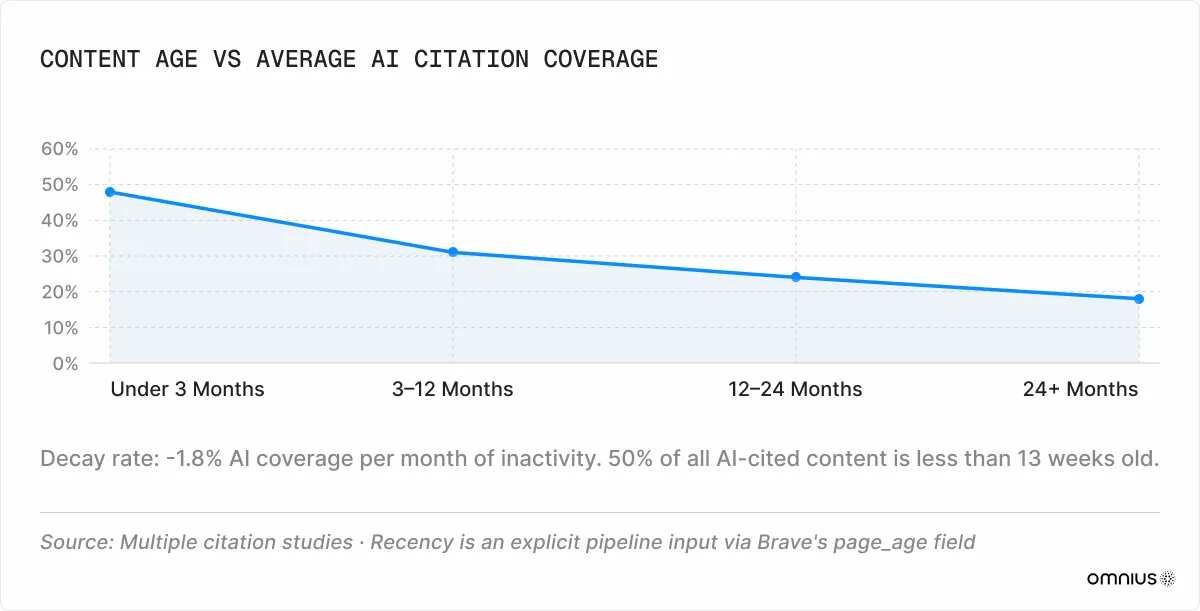
50% of AI-cited content is less than 13 weeks old. AI coverage decays at roughly -1.8% per month of inactivity. Brands that update content monthly see 23% higher AI coverage than those with stale equivalents (Erlin, 2026). A visible publication date and a recent "last updated" timestamp are direct inputs to the retrieval pipeline.
What you should do: Update content at least every three months, and make sure your updatedAt metadata reflects the new date.
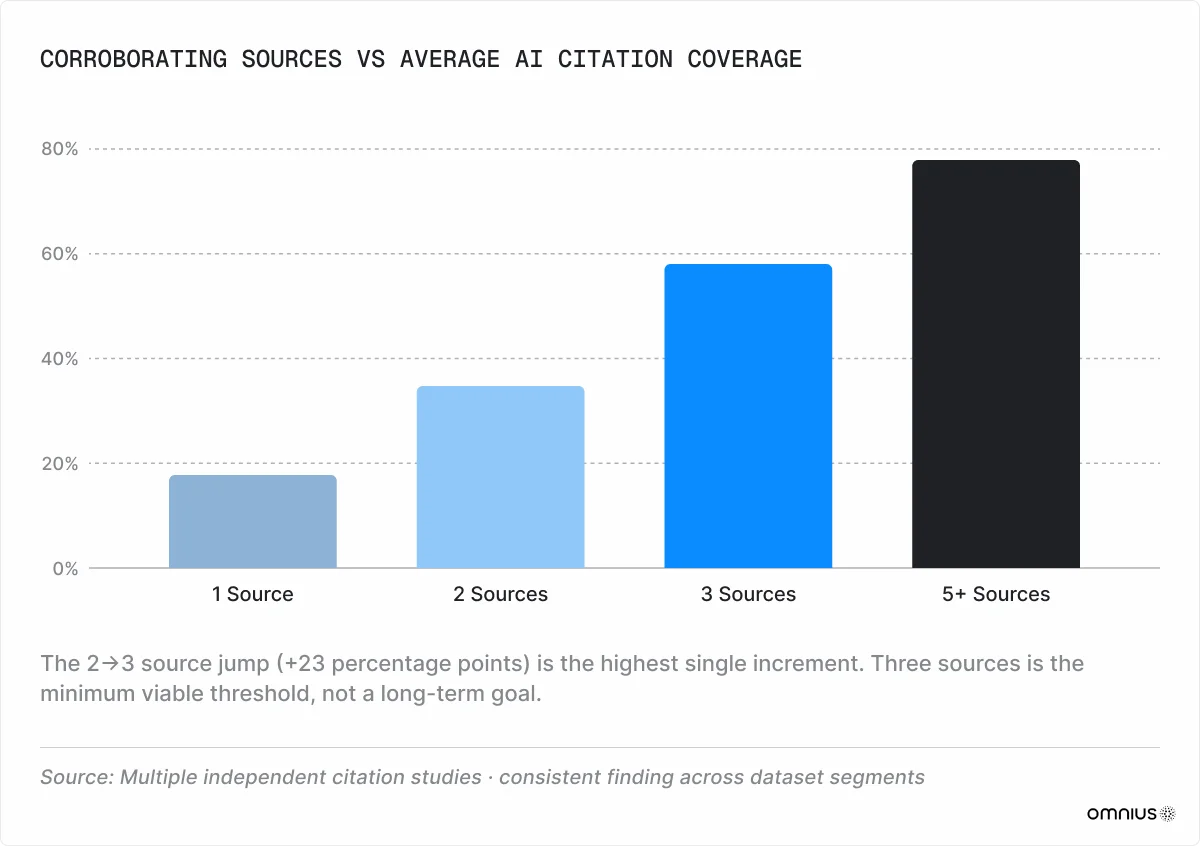
5. Corroborating Source Density
Claude cross-references claims before citing, and the data shows a clear gradient between source count and AI coverage (Erlin, 2026):
- 1 source: 18%
- 2 sources: 35%
- 3 sources: 58%
- 5+ sources: 78%
The steepest single increment is from 2 to 3 sources – a 23 percentage-point jump. Three corroborating sources are the minimum threshold for consistent citation.
What you should do: Build corroboration for your key claims across independent sources. Contribute proprietary data to industry reports and analyst briefings. Co-publish case studies with customers so the results appear on both domains. Write for trade publications that cover your space. Pursue reviews on G2, Capterra, and relevant aggregators.
6. Technical Parseability
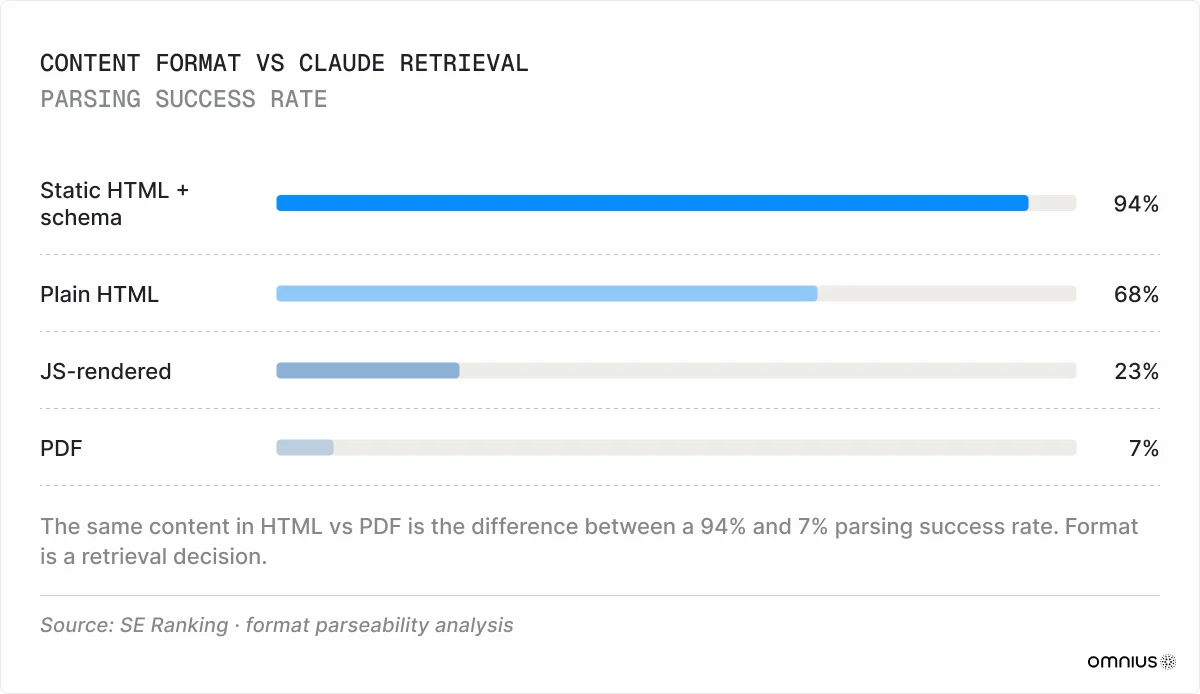
Static HTML with schema markup parses successfully 94% of the time. Plain HTML with no schema: 68%. JavaScript-rendered content: 23%. PDFs: 7% (Erlin, 2026). If your website relies on client-side JavaScript rendering, visitors can see the content, but Claude may not, resulting in retrieval failure.
What you should do: Check how Claude sees your pages by disabling JavaScript in your browser and loading key pages. If the content disappears, Claude can't see it either. Ensure that all high-value pages, such as landing pages, product documentation, comparison pages, and FAQ sections, are served as static HTML or use server-side rendering.
7. Domain Authority
SE Ranking's 2025 analysis of 2.3 million pages found domain traffic is the strongest single predictor of AI citations, with a SHAP value of 0.63. High-traffic domains earn 3× more AI citations than low-traffic equivalents. Sites with more than 350,000 referring domains average 8.4 AI citations per response. Authority is a floor, not a guarantee.
What you should do: Build domain authority through consistent earned media, backlink acquisition from industry-relevant publications, and digital PR campaigns that generate coverage on high-authority news sites. Publish original research, proprietary benchmarks, and data studies that naturally attract inbound links. Track your backlink profile and focus on link quality over volume.
How To “Rank” on Claude as a B2B Business: A Four-Layer Approach
The goal: be easy to retrieve, easy to rerank, easy to cite, and hard to distrust.
Claude SEO operates upstream and downstream simultaneously. In the early stages, content needs to be discoverable by Brave Search and technically accessible to Claude's crawlers. Later on, content needs to survive prompt-specific reranking by being precise, attributable, and directly useful to the actual question asked.

Layers 1 and 2 are directly documented by Anthropic. Layer 3 hasn’t been explicitly documented by Anthropic as a Claude ranking signal, but it’s a strong strategic inference consistent across multiple independent studies. Layer 4 is supported by both the GEO literature and Anthropic's own observation that source-quality heuristics were added after early agents over-selected brand-owned content.
Layer 1: Fix the Silent Failures First
Most brands failing on Claude never reach content evaluation.
According to Ahrefs, ClaudeBot blocking rates increased 32.67% in 2025. A BuzzStream study found 71% of publishers who block at least one AI training bot also inadvertently block at least one retrieval bot.
The bots are often blocked unintentionally. A security team may write a robots.txt wildcard or Cloudflare rule to block GPTBot or ClaudeBot and prevent AI training data collection. That rule then catches all three Anthropic crawlers. The result is complete invisibility in Claude's live answers. And because there's no error notification, your team may never realize it happened.
In robots.txt, you should explicitly allow all three bots:
User-agent: ClaudeBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
Audit Cloudflare separately. Bot Fight Mode is enabled by default and does not distinguish between malicious bots and legitimate AI crawlers. Check server logs 48–72 hours after any configuration change to confirm the crawlers are getting through.
Verify Brave Search indexing by searching search.brave.com for key commercial queries. Remember that server-side rendering is required for high-value pages, with static HTML achieving the highest parsing success. AI crawlers have a Time to First Byte patience window of approximately 200ms (Am I Cited, 2026). Unlike Googlebot, which retries, AI crawlers abandon slow-loading pages before rendering any content.
Layer 2: Compete With Every Passage
Claude’s citation unit is a self-contained passage of 46–100 words that can answer a query without surrounding context. Every section of every page competes independently. A strong opening section on a weak page will outperform a weak opening section on a strong page.
Open every section with the direct answer of 40–60 words, naming the entity, the claim, and the scope. Make every passage individually interpretable:
- Repeat the subject noun rather than using pronouns.
- Include the entity name and date within the passage.
- Avoid cross-references to adjacent sections.
- Target one verifiable, attributed data point per 150–200 words.
The reranker scores passages against the exact prompt, not the general topic. Mirror the exact phrasing patterns of real purchase-intent queries instead of writing for a general audience.
Layer 3: Implement Schemas
Every content page targeting Claude citation needs schema: a named author with a linked biography, institutional affiliation, and relevant expertise signals. Schema implementation adds +27% lift in AI extractability (GrackerAI, 2026). Minimum requirements include:
- Article + Person for all editorial content
- FAQPage for Q&A sections
- HowTo for step-by-step guides
- Organization + sameAs links for company pages
- SoftwareApplication for product pages
FAQ sections with FAQPage JSON-LD schema deliver a measured +28% AI coverage lift within 21 days of implementation (Erlin, 2026).
Layer 4: Build Citation Authority
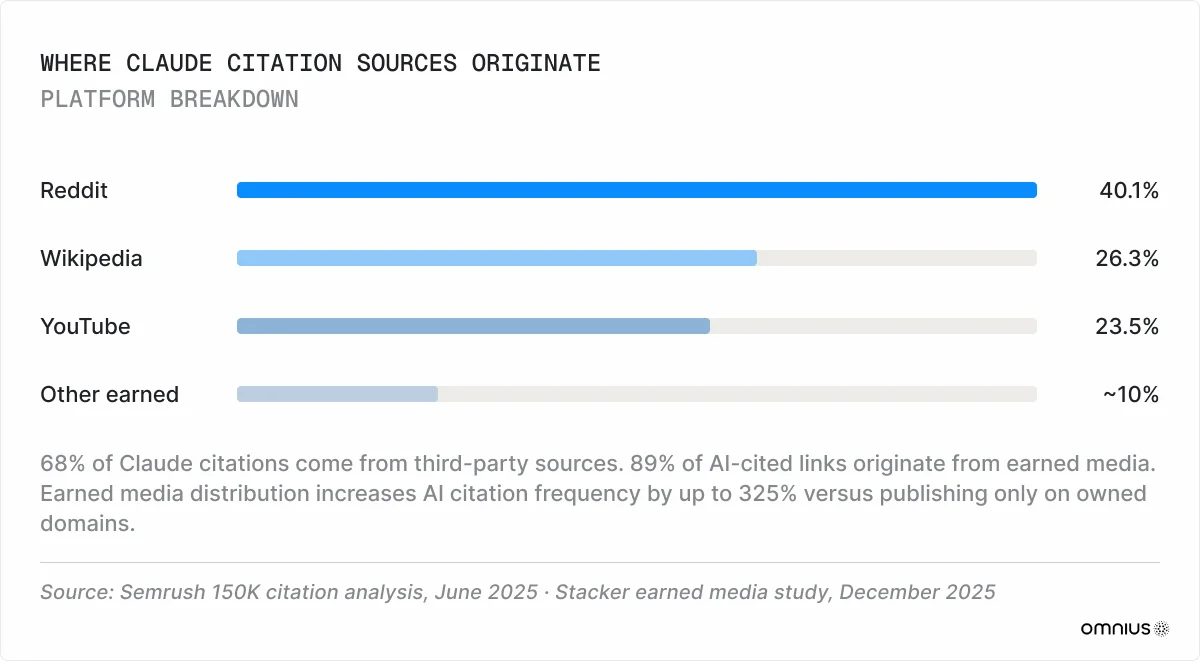
Earned media is a primary channel for Claude visibility. In its 2025 150K citation analysis, Semrush found that 68% of Claude citations come from third-party sources rather than brand-owned channels. 89% of AI-cited links originate from earned media (MuckRack, 2025). Earned media distribution across a wide publication set increases AI citation frequency by up to 325% compared to publishing only on an owned domain (Stacker, 2025).
The most-cited platforms in Claude's retrieval pool are Reddit (40.1% of all LLM citations), Wikipedia (26.3%), and YouTube (23.5%), as per Semrush data. B2B brands can achieve third-party corroboration by participating in specific subreddits, publishing technical walkthroughs on YouTube, and creating a company Wikipedia page.
The underlying mechanism is information gain. Claude references primary sources over summaries by design because summaries can be reconstructed, whereas unique data cannot. Benchmarks, proprietary datasets, and case studies with methodology and named outcomes offer more reasons for citation than aggregated content.
Measuring Claude Visibility
There is no native Claude analytics tool. Measuring visibility requires assembling multiple signals manually.
To track Claude visibility, build a set of 20–30 prompts that reflect how your buyers actually research solutions. Run them across Claude monthly and record whether your brand appears, how it's described, and which competitors show up alongside it. You can do so manually or using an automated solution like Atomic AGI.

These five signals give you a working picture of where you stand with Claude, what needs fixing, and what to focus on first:
- Crawler access
- Citation flow rate
- Prompt coverage
- AI share of voice
- Citation sentiment
1. Crawler Access
Crawler access tells you whether Claude bots are actively crawling your priority pages. It’s a fundamental signal you should check first before investing in any content changes. If the crawlers aren't reaching your pages, every other metric is irrelevant.
How to measure: Access your web server logs and filter for ClaudeBot, Claude-SearchBot, and Claude-User agents. Server logs record every bot visit to your site, including which pages were requested, when, and by which crawler.
2. Citation Flow Rate
The citation flow rate (CFR) is the ratio of AI citations to search impressions, calculated as AI Citations ÷ Search Impressions × 100. It shows you how effectively your existing search visibility converts into Claude citations.
A page can rank well on Google and receive thousands of impressions but produce zero Claude citations. CFR exposes that gap.
How to measure: Calculate CFR per page and per query cluster, not as a site-wide average. A site-wide number will mask pages that perform well and pages that are completely invisible.
.webp)
3. Prompt Coverage
Prompt coverage is the share of relevant purchase-intent queries that surface your brand. This is the closest equivalent to keyword tracking in traditional SEO, but instead of checking where you rank on Google, you're checking whether Claude mentions you at all.
How to measure: Include the following prompts in your tracking set, run them monthly, and note how often your brand appears:
- Category queries: best [category] tools for [use case]
- Direct comparisons: [your product] vs [competitor]
- Problem-oriented queries: how to solve [problem your product addresses]
4. AI Share of Voice
Share of voice (SoV) reveals how much of the conversation Claude gives to you versus your competitors for a given topic or category. We calculate it as your brand mentions ÷ total market mentions × 100.
How to measure: Track two variants separately. Entity-based SoV measures brand appearance as a named recommendation and maps directly to business outcomes. Citation-based SoV measures brand content cited as a source. It’s a leading indicator of future entity SoV. Citation-based SoV is what gets built first. Entity SoV follows.
5. Citation Sentiment
Citation sentiment tells you how Claude frames your brand when mentioning it. There's a difference between Claude recommending your product as a first choice, describing it neutrally as one of the options, and listing it at the bottom of an alternatives list.
How to measure: Document how and where your brand appears in Claude’s responses to relevant queries, and track changes month-over-month. Track positioning categories like recommended, described, and listed, or sentiment categories like positive, neutral, and negative.
Measuring Issues To Consider
A common problem is undercounting. The session is registered as direct traffic in GA4 when users follow a Claude recommendation but arrive through Google search, by typing the URL, or via a bookmark. True Claude contribution may be 2–3× what referral tracking captures.
There’s also error exposure. Monitored brands detect AI factual errors in 14 days on average, while unmonitored brands take 67 days (Erlin, 2026). During this 53-day gap, Claude is serving wrong and potentially buyer-deterring information about your brand across thousands of queries.
Still, McKinsey 2025 data shows that only 16% of brands track AI search performance in any form. The other 84% can't see which pages LLMs cite, which queries trigger mentions, or whether they are serving inaccurate information about their brand. Without that visibility, content and infrastructure improvements are guesswork. The gap against competitors who are tracking widens with every quarter.
Solve for Claude. The Rest Follows.
Claude sets the highest bar for content quality in current AI search. Content that satisfies Claude's citation requirements - factual density, author credibility, primary source attribution, third-party corroboration, neutral analytical register - performs better on every other AI platform.
There is also a first-mover advantage. Claude's training data, Brave index authority, and source preference patterns all build on previous citation events. The benefits compound, and they make it harder for competitors to catch up the longer they wait.
Most B2B companies don't have the cross-functional infrastructure to run this alone. At Omnius, we handle the full B2B GEO stack for SaaS, Fintech, and AI companies, helping them become market leaders through organic positioning. Reach out to take your share of AI search before the window narrows.
Frequently Asked Questions
How does Claude get its data?
Claude’s baseline knowledge comes from training data, collected by ClaudeBot's web crawl and embedded into model weights. For queries requiring current information, Claude retrieves results from Brave Search through an RAG pipeline. A page's Brave indexing status determines whether Claude can find it. Claude-SearchBot indexes pages for this retrieval, and Claude-User fetches specific pages in real time during active conversations.
How long does it take to get cited by Claude?
There’s no fixed timeline, and it depends on your starting position and priorities. According to 2026 Erlin estimates:
- Technical changes and schema implementation can produce results in 2–4 weeks.
- Content structure updates can make an impact in 4–8 weeks.
- Authority-building activities like review accumulation take effect after 3–6 months.
Claude is the slowest of the major AI engines to cite new content. It takes longer because its Constitutional AI training applies a higher level of scrutiny, and because Brave Search needs to index the content before Claude can access it.
There are also two distinct timelines to consider. For live retrieval, citations can appear within weeks of publishing strong content. For parametric knowledge, the cycle follows Anthropic's model training cadence, which is typically 6–12 months between major updates.
Is Claude actually the best AI?
That depends on what you're measuring. When it comes to B2B search visibility, Claude achieves the highest session value and conversion rate among AI engines (Omnius, 2026). Its user base skews toward enterprise buyers and technical decision-makers, which makes it the most commercially valuable AI traffic source for SaaS and Fintech companies. Claude also distributes visibility more broadly than ChatGPT or Perplexity, giving mid-market domains a realistic chance of being cited.
Whether it's the "best AI" in general is a different question. But for B2B companies focused on being found during vendor research, it is currently the highest-value channel.
Author’s Disclaimers
This report is built on documented mechanisms, statistical analysis, and consistent external evidence. The described pipeline is the most coherent reconstruction of available evidence as of May 2026. It is not a confirmed map of Claude's ranking system, because no such map exists publicly.
Anthropic has not published a ranking algorithm, signal weightings, or quality rater guidelines equivalent to Google's. What exists is a set of documented retrieval primitives from which a plausible pipeline was reconstructed. Anthropic will continue to update Claude's retrieval architecture without announcing it.
The signals that matter today, such as factual density, author credibility, Brave indexability, and third-party corroboration, are grounded in mechanisms that are unlikely to reverse. The specific weights and thresholds will shift. The underlying logic of what Claude is trying to do - surface the most trustworthy, verifiable, useful answer to a specific prompt - will not.





.png)

.svg)








.svg)


























